Disclaimer: The text below is written for a wide audience. This means that the tech vocabulary is deliberately kept simple and, to some readers, the explanations may appear a bit long-winded.
Week zero
The biggest changes we implemented in our first week of existence are the modifications to the incentive mechanism, that is, the way contributions are rewarded. We feel it is important to have an open discussion about this, and as a starting point we are sharing our ideas here, providing context and references to the changes.
Before jumping into the details, we will translate our mission and goals into concrete, actionable points, and work out the expected impact and implementation details from there.
Our goals…
One major goal is to deliver good models, that can be used to develop real-world applications. To assess whether a model is “good” we measure the “loss value” on random texts (samples) selected from a particular open source dataset. A lower loss value indicates that the model is better at predicting each following word (token), and so miners are challenged to produce the model with the lowest possible loss.
…translated into miner incentives…
To this end, the miner posting the best model should get the biggest (or even the full) reward. As another miner can take the top model, improve it just a little, and upload it, this could quickly become unfair and disincentivizes putting significant effort into training a good model from the start.
…and fair distribution of mined TAO
Therefore, miners that see their model being improved upon and posted, should not lose their fair share of the reward. This introduces a contradiction, which in various subnets is resolved by giving the first-published model a head start, by lowering their loss values with some fixed advantage percentage, before comparing them to the loss values of competing models.
This is the state of affairs in other subnets at the time SN29 was created.
The core issue: rewarding work or result?
In an ideal world we would want to reward miners for the work they have put into training, in the form of GPU training hours, efficient training algorithms or a combination of the two. We can however only assess the published result, so for that reason we reward the result, as a proxy for work performed. Such a mechanism adds a significant risk to the overall process, as is observed in other subnets: stagnation. Top models keep earning rewards, while no mining activity is performed.
Not exactly incentivizing good behavior?
Handing out a fixed advantage has a huge drawback: there is no incentive to publish a model that does not exceed the improvement required to beat the advantage percentage. Therefore, the objectively best model does not always win, and will often not even be published, as the miner will keep trying to improve it beyond the advantage threshold. This cascades into even more drawbacks. Summing them up:
- Small improvements are not published
- Miners cannot improve on small improvements of other miners, and therefore can’t cooperate to eventually produce a better model than the top model
- Algorithmic improvements or technical adjustments to the model (some would say “clever tricks”) improving the top model by a small amount, are not published
- Top miners are not incentivized to publish small improvements to their own top models
- Top miners may even postpone publishing larger improvements, as they keep their powder dry to prepare for the situation where someone posts a model that only slightly exceeds the threshold
- The worst drawback: the competition stagnates before the best possible model is created and posted
Flawed game dynamics and risks too big to take
Things are even worse when considering the typical loss curve seen when training a model, for example looking at the “16B Params” part of this graph:
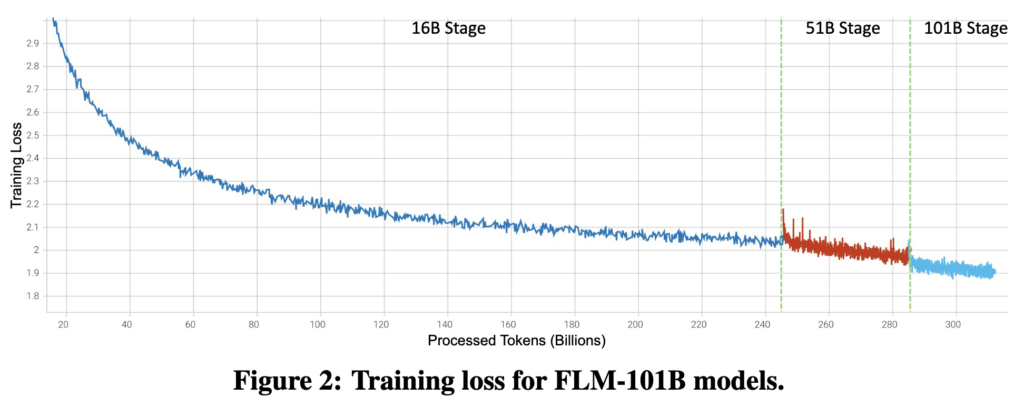
This is clearly not a straight line. Each following percent of improvement will require training more samples, and therefore more GPU time. A fixed advantage percentage implies that every following better model will require even more training, up to the point where the risk of spending resources on training without any form of reward is just too big to take. So then model improvement stagnates – while the graph clearly shows that it never really flattens out.
Solving it all with decaying advantage?
By decaying the advantage given to the oldest model (see relevant commit on GitHub), small improvements will eventually be rewarded. This eliminates the drawbacks summed up above, and in fact turns them into forces for good:
- Small improvements will be rewarded, after the advantage an older model gets has decayed
- Clever tricks that have limited impact on loss, can still lead to a reward
- All miners are incentivized to upload small improvements
- Miners can build upon each other’s work
- Mining is accelerated and will reach a lower loss, faster, compared to a subnet with a static advantage
- Miners will only keep getting rewards if they keep mining, i.e. we are closer to rewarding work rather than rewarding results
This in turn leads to the additional advantage that mining can become profitable on smaller setups with lower budgets than were seen until now on for example SN9, significantly lowering the barrier to entry.
How long must I wait…
The decay rate is currently 0.5% per epoch, which amounts to roughly 50% per week. Given an initial advantage of 0.4%, this means that a second model that is, for example, 0.2% better than the first model, will start rising to the top roughly one week after the first model was published. Note that the publishing date of the second model is irrelevant for this comparison: it is only the advantage given to the older model that decays – eventually a new, better model will always rise to the top.
And then?
A third model, that improves the second model by, for example, 0.1%, will have to wait roughly two weeks, counted from the date the second model is published, before the 0.4% advantage, now given to the second model, has decayed to below 0.1%. From that point on, the third model will receive the largest share of miner rewards – and rightly so, as it has the lowest loss values. These examples illustrate how the advantage moves from model to model, due to its decaying nature.
Coming up
In the next blog post on incentive, we will explain how loss values are converted into win rates, then into weights, and eventually into TAO handed out to miners.
0 Comments